Ntire2024非均匀浓雾去除挑战赛报告
Ntire2024非均匀浓雾去除挑战赛报告
介绍
- 图像去雾任务缺乏标准化的测试基准。
- 保持
一致的光照条件和参考图像与模糊图像之间的逐像素对应是数据收集的关键挑战。 - 历届比赛数据集:
- O-HAZE和I-HAZE(Ntire2018,轻度均匀雾)。
- DENSE-HAZE(Ntire2019,均匀浓雾)。
- NH-HAZE(Ntire2020、2021,非均匀雾)。
- NH-HAZE2 (Nitre2021,非均匀雾)
- HD-NH-HAZE(Ntire2023,高清非均匀雾)
- 本届比赛数据集:
- DNH-HAZE(高清非均匀浓雾,4000×6000或6000×4000) 。
- 训练数据 40对
- 验证数据 5对
- 测试数据 5对
- DNH-HAZE(高清非均匀浓雾,4000×6000或6000×4000) 。
- 比赛目的:
- 探索最新的去雾研究趋势。
- 强调高质量数据集的可用性。(DNH-HAZE)
- 评价指标
- PSNR (Peak Signal to Noise Ratio)。峰值信噪比。
- SSIM (Structural Similarity)。结构相似性。
- LPIPS (Learned Perceptual Image Patch Similarity)。模型评估图像的感知质量。
- MOS (Mean Opinion Score)。人工评估图像的感知质量。
方案排名
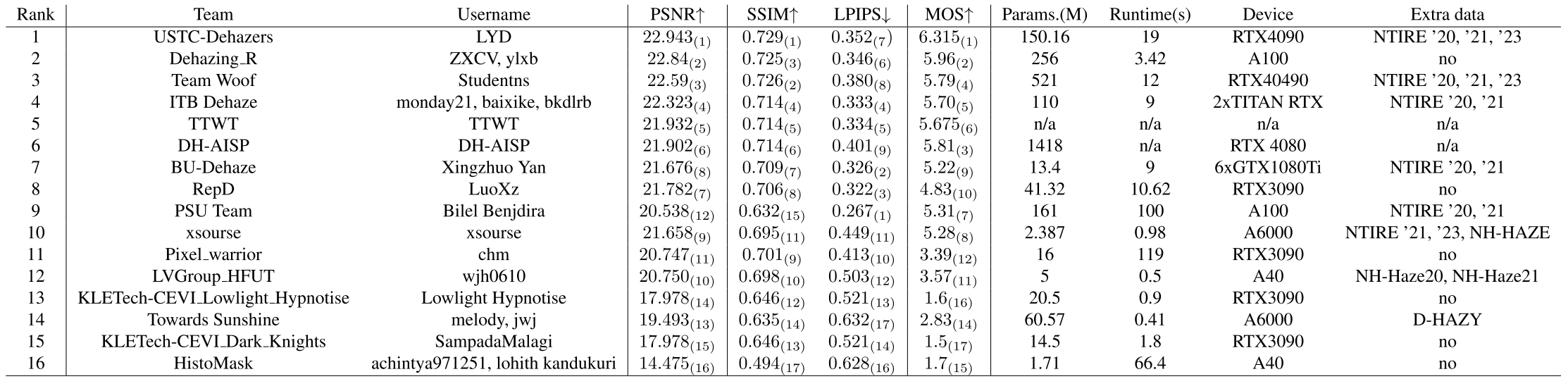
USTC-Dehazers
Coarse-to-Fine Hybrid Network for Dense and Nonhomogeneous Dehaze
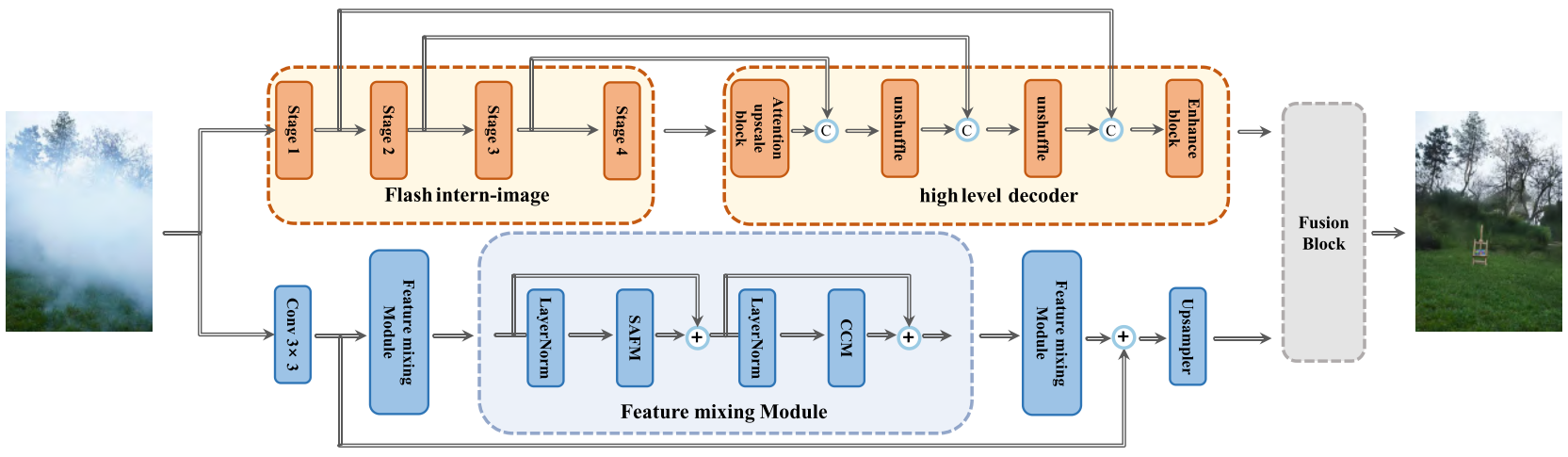
- 基于双分支模型作为整体框架。
- 迁移学习分支中(上半),Flash intern-image融合了可变形卷积Deformable Convolution v4 (DCNv4),具有更强的远距离建模能力和自适应空间聚合能力。[增加网络的去雾能力]
- 细节提取分支中(下半),使用轻量级空间自适应特征调制(Spatially-Adaptive Feature Modulation,SAFMN),通过引入选择性注意机制,将不同层次的特征动态融合,增强模型对关键信息的感知能力。[应对高分辨率的挑战]
- 引入合成数据。[缓解训练样本稀少的困境]
- 引入EfficientVit-SAM作为特征提取器,构建了一种新的增强感知损失。[降低雾霾的残留]
Dehazing_R
DehazeDCT: Towards Effective Non-Homogeneous Dehazing via Deformable Convolutional Transformer
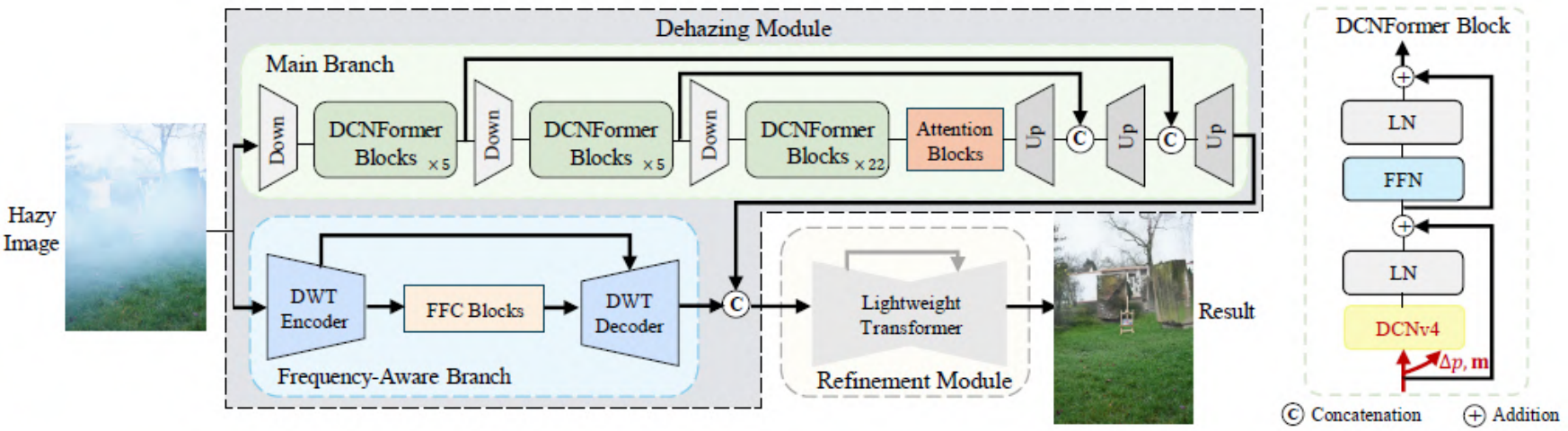
- Dehazing Module第一阶段去雾模块。
- 学习雾图像到清晰图像的颜色和纹理映射。
- 双分支。
- Main Branch:基于Deformable Convolution v4的类Transformer架构。
- Frequency-Aware Branch:集成了一个频率感知分支,方便频率特征的获取。
- 使用L1损失、SSIM损失、感知损失以及GAN对抗损失。
- Refinement Module第二阶段细化模块。
- 为了进一步还原细节和纹理,输出逼真的效果。
- 采用了一种基于Retinex的轻量级Transformer网络。
- 使用L1损失、SSIM损失和感知损失。
Team Woof
Two Stage Training and Multi-Scale Attention Head For Dehazing
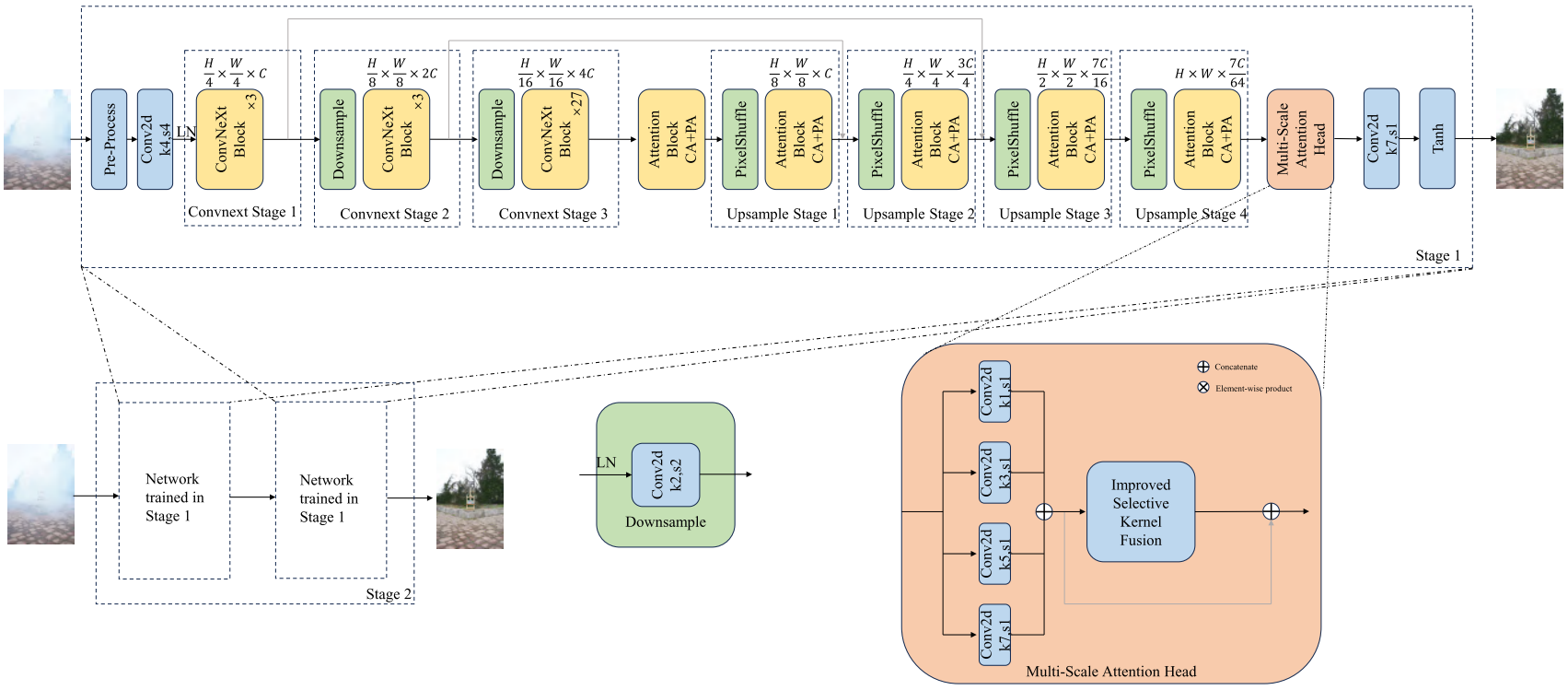
- 基于ITB-Dehaze和DWT-FFCGAN。
- 引入多尺度注意头。并行多尺度卷积核(类似MixDehazeNet)。
- 通道注意力和像素注意力块(CA+PA,类似FFANet)。
ITB Dehaze
A Fine-Tuned Self-supervised End-to-end Solution to NonHomogeneous Dense Dehazing via Transformer
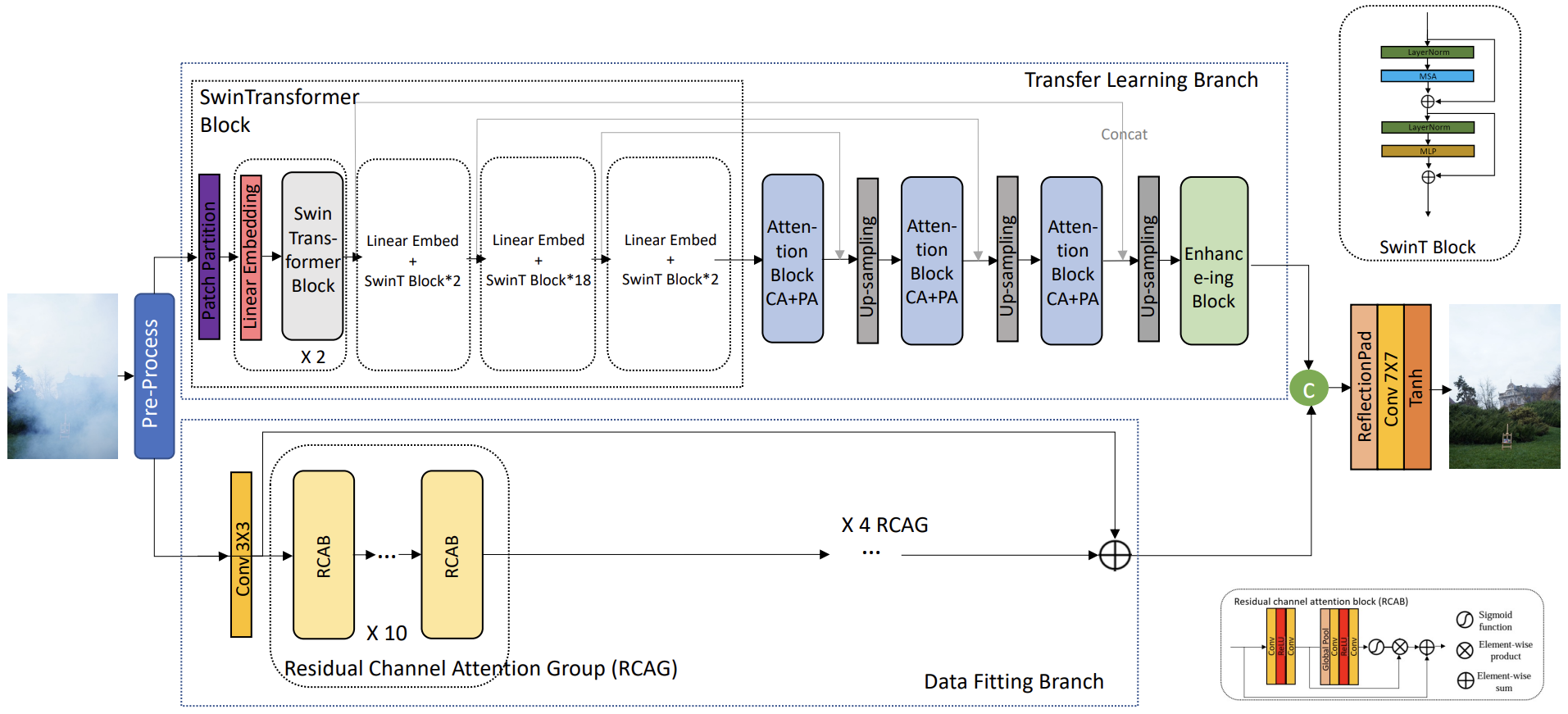
- 基于Ntire2023Best网络架构。
- 对往年的数据(NH-HAZE1、NH-HAZE2)进行了三通道伽马矫正,使往年(2020、2021)的数据在色彩与亮度方面与今年(2023)的数据更匹配。
- 双分支网络。
- Transfer Learning Branch:
- 采用在ImageNet上预训练的Swin-Transformer V2模型提取雾图像的有意义的多尺度特征。
- 采用迁移学习的思想,使用ImageNet预训练模型初始化Swin-Transformer,使系统能够基于之前低级任务中学习到的知识。
- 通道注意力和像素注意力块(CA+PA,FFANet)。
- Data Fitting Branch:
- 仅从NH-Haze数据集学习,来补充从预训练模型中学到的知识。
- 级联残差通道注意网络(Residual Channel Attention Network,RCAN)和从头开始训练可以很容易地在参数数量和映射能力之间找到一个很好的平衡。
- 传统卷积层中没有出现下采样操作,因此不会丢失精细特征。
- 为了保证泛化性能,该分支被设计为轻量级。
- 通过注意力模块和跳跃连接,加上一个简单的融合模块,将两个分支的结果集成在一起,输出去雾后的图像。
- Transfer Learning Branch:
- 采用了半监督自监督方法,克服了数据样本的不足。为未标记的数据生成合成标签,并使用低学习率和模型的正则化设置在其上再次训练模型。利用这种方法引入了利用更多未标记数据进行培训和改进的可用性。
TTWT
Improved NonLocal Channel Attention for NonHomogeneous Image Dehazing
- 基于Ntire2023Best网络架构。
- 进行以下改进
DH-AISP
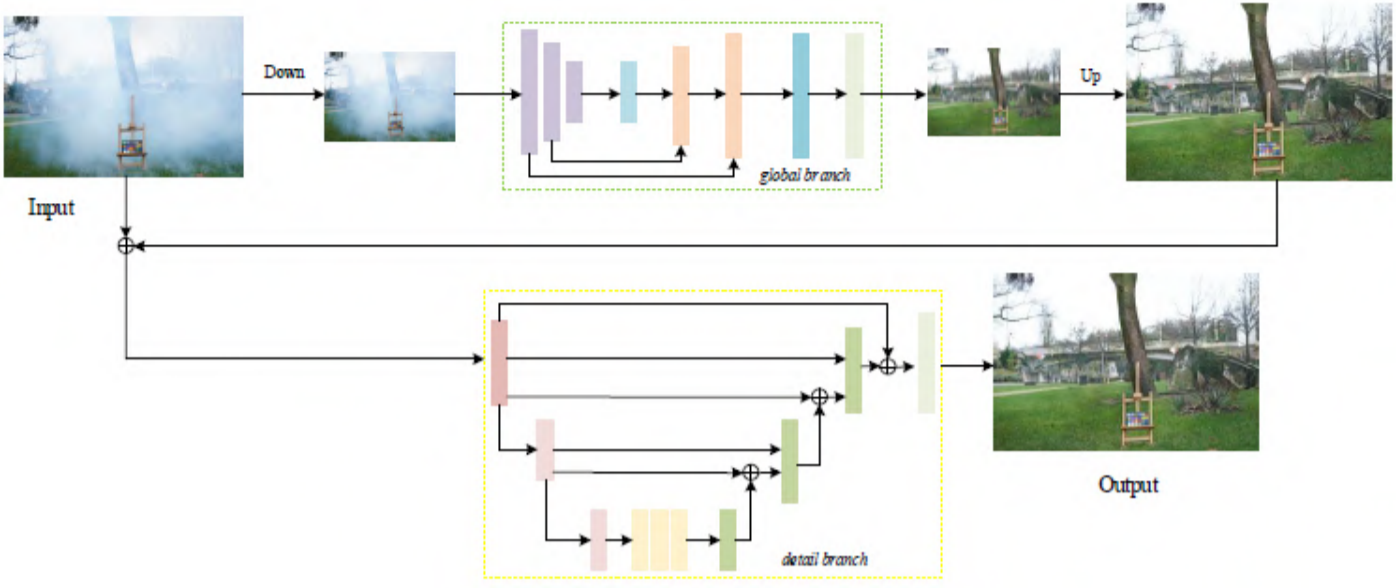
- 基于精细双分支模型。
- 全局分支 (global branch):在低分辨率下学习原始图像与雾图像之间的映射关系,相对于原始分辨率具有更大的感受野,可以通过周围区域恢复被雾破坏的信息。
- 细节分支 (detail branch):学习输入图像与低分辨率恢复图像之间的细节差异。
BU-Dehaze
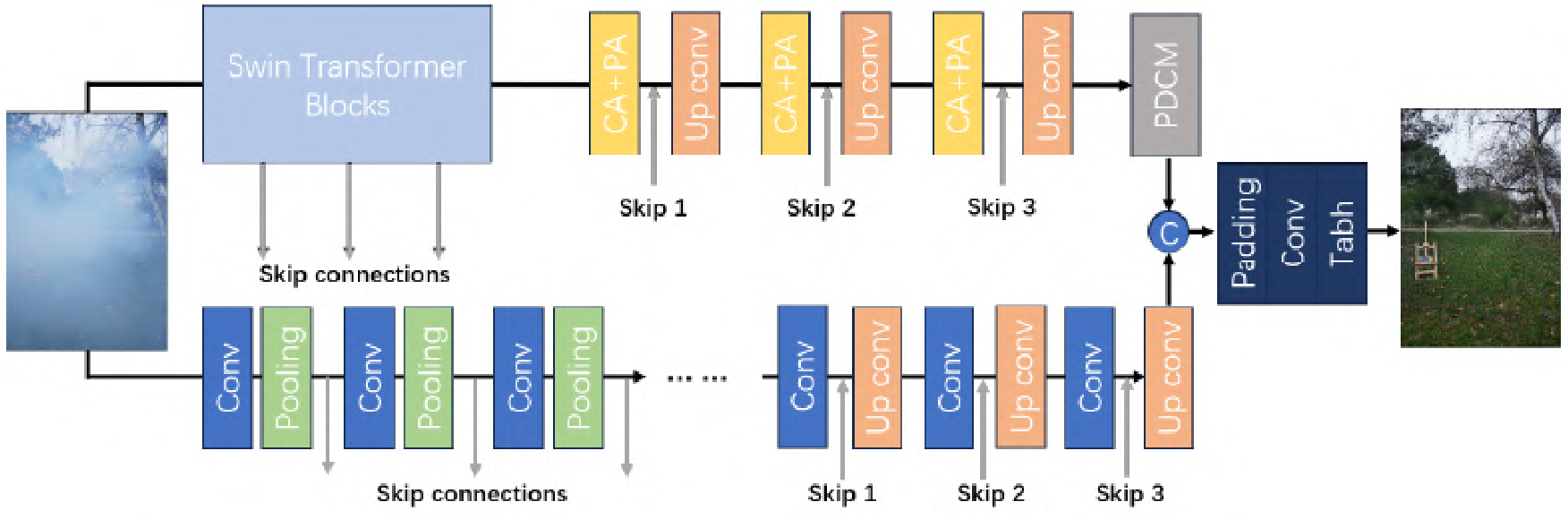
受DW-GAN启发,开发了一种数据预处理技术,旨在使增强数据的分布与目标数据的分布更紧密地保持一致。
双分支结构。
- 第一个分支中,利用在ImageNet数据集上预训练的Swin-Transformer V2模型和自注意力机制,从雾图像中提取相关的多尺度特征。采用迁移学习的概念,使用ImageNet预训练模型初始化Swin-Transformer,从而使系统能够利用到从先前的低级任务中获得的知识。
- 第二个分支中,采用U-Net架构,通过专门关注目标数据领域来补充第一个分支。
方案中的关键设计
- 迁移学习。
- 引入合成数据。
- 可变形卷积。 (Deformable Convolution v4)
- 感知损失函数。
- 双分支结构。
- DWT-Encoder。
- 并行多尺度卷积核。
- 通道注意力和像素注意力。 (CA+PA)
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 PlanZ!







