服务器上模型训练的常用命令
服务器上模型训练的常用命令
深度学习训练过程中,模型越大,参数越多,占用的显存越大(如VGG16参数量约138M,训练显存需求10-12G;Transformer在BERT-base中参数量约110M,训练显存需求12-16G;Stable Diffusion V2.0参数量约890M,训练显存需求16-24G。显存占用因具体输入大小、实现细节和优化手段而异)。
通常个人设备的显存难以满足训练模型的要求,需要将训练代码上传到配有更好显卡(常用GPU如RTX4090-24G,V100-16/32G,A100-40/80G。不同显卡除显存之外,还存在着架构、计算性能、内存带宽等方面的区别,适用于不同的任务场景)的服务器上进行模型的训练工作。
远程连接服务器
无论是连接自己的服务器资源还是连接云服务平台(如阿里云、腾讯云、恒源云等)租赁的服务器,都可以使用MobaXterm、Xshell或是Windows远程桌面连接等远程终端控制工具,通过配置以下参数进行远程连接:
- 主机地址:IP地址如(10.16.0.41)或域名如(gpuplatform.com)
- 端口号:如(30841;2333等)
- 用户名:如(root;superman;spiderman等)
- 密码:如(122333;rHesBZNZz4dhd7hS8MzMUc4E3twRXTkw等)
以恒源云、MobaXterm为例:
在恒源云平台注册账号,进入控制台,在实例与数据—我的实例页面点击创建实例,选择需要租用的显卡类型并创建实例。
通常云服务平台在创建实例时会提供操作系统选择以及框架的预装,如选择使用Linux系统、V100-16G显卡、Pytorch2.0.0框架、Cuda11.8.0、Python3.8。
完成创建之后即可在控制台—实例与数据—我的实例页面获取到实例信息以及远程连接参数。

复制登录指令和密码即可获取以下内容:
ssh -p 37587 root@i-2.gpushare.com
rHesBZNZz4dhd7hS8MzMUc4E3twRXTkw
从中可以提取出主机地址(i-2.gpushare.com)、端口号(37587)、用户名(root)、密码(rHesBZNZz4dhd7hS8MzMUc4E3twRXTkw),打开MobaXterm,点击左上角Session,在以下窗口输入对应的参数。

点击OK,连接过程提示需要输入密码,复制实例的登录密码,在命令行处右键粘贴密码并回车确定(在命令行处点击右键就是直接粘贴,粘贴完后命令行处的密码不会显示,直接回车即可)。

顺利连接到刚刚租赁的服务器。

Linux常见命令
首先熟悉一下Linux系统下的一些基础常见命令:
ls: 显示当前目录的内容pwd: 显示当前目录的路径cd: 改变目录cd 想进入的目录: 进入想进入的目录,目录有以下几种写法:/: 根目录,如cd /表示返回到根目录.: 当前目录,如cd ./a表示进入当前目录下的 a 目录中,也可以直接简写成cd a..: 上级目录,如cd ..表示返回上一级目录,cd ../b表示返回上一级目录并进入上一级目录中的 b 目录中~: 默认工作目录,可自定义,通常表示 /home/用户名
touch: 创建新文件或修改现有文件的时间戳touch [选项] 文件名: 用于创建普通文件,如果文件存在则表示修改当前文件时间(访问时间和修改时间),选项可有以下参数(部分):-a: 只更改访问时间-c,--no-create: 不创建任何文件-d,--date=字符串: 使用指定字符串表示时间而非当前时间-m: 只更改修改时间-r,--reference=文件: 使用指定文件的时间属性而非当前时间
mkdir: 创建新目录mkdir [选项] 目录名: 用于创建新的目录,如果指定的目录已存在,将会返回一个错误信息,选项可有以下参数(部分):-m,--mode=MODE: 设置新建目录的权限,类似于chmod,如mkdir -m 700 testfold-p,--parents:递归创建目录,必要时自动创建父目录。如果指定的目录已存在,不会报错,如mkdir -p /root/test1/test2/test3,如果 test1 和 test2 不存在,该命令会自动创建这些目录-v,--verbose:显示命令执行过程中的详细信息,即显示每个创建的目录
cat: 查看文件内容cat [选项] 文件: 用于查看文件的内容或将多个文件合并输出,选项可有以下参数(部分):-b,--number-nonblank: 显示非空行的行号-n,--number: 显示每一行的行号-s,--squeeze-blank: 多个空行连续出现时,压缩成一行空行-v,--show-nonprinting: 显示非打印字符-E: 在每一行的末尾添加 $ 符号
cp: 复制文件或目录cp [选项] 源文件或目录 目标文件或目录: 基本使用方法,选项可有以下参数(部分):-b,--backup=CONTROL: 创建备份文件,若目标文件已经存在,添加一个备份拓展名;备份文件的类型由选项 CONTROL 指定,默认为none-i,--interactive: 交互模式,复制文件或目录前先询问是否覆盖-n,--no-clobber: 不覆盖已经存在的文件,不进行复制操作-p,--preserve: 保留文件属性,包括所有权、访问时间、修改时间和权限-r,--recursive: 递归复制整个目录及子目录;若要拷贝目录下所有内容,必须使用此选项-u,--update: 如果目标文件比源文件旧,或者目标文件不存在,就会被覆盖掉
cp 源文件 目标目录: 复制单个文件cp 源文件 目标目录/新文件名: 复制单个文件的同时重命名它cp 文件1 文件2 文件3 目标目录: 复制多个文件cp -r 源目录 目标目录: 复制单个目录cp -r 目录1 目录2 目录3 目标目录: 复制多个目录
mv: 移动或重命名文件或目录mv [选项] 源文件或目录 目标文件或目录: 使用方法和参数与cp命令非常类似,可类比cp使用。mv命令可以改变文件在文件系统中的位置或名称。区别于cp指令,cp后的文件个数是增加的,所以会额外占用与原文件相同大小的磁盘空间,mv则不会。在同一个目录内对文件进行移动的操作,实际上可以理解为重命名操作。
rm: 删除文件或目录rm [选项] 文件或目录: 删除文件或目录,选项可有以下参数(部分):-f: 直接删除,不需要确认-r: 递归删除(用来删除目录)-i: 交互模式,删除前逐一询问-v: 显示步骤-d: 只删除空目录
clear: 清空当前终端屏幕上的内容
上传文件并配置环境
文件上传
可以使用专用的文件传输软件如Xftp连接服务器并上传文件(与上述远程连接服务器过程类似),或者直接在MobaXterm中打开对应文件夹右键选择 upload to current folder 进行文件上传。
如果文件较大(如数据集等),为了提高传输效率可以在上传文件之前先将其压缩成zip文件,上传成功后,使用 cd 命令切换到上传目录,在该目录下使用 unzip 命令进行文件解压缩。
1 | unzip 数据集.zip |
注意:unzip解压zip文件最大不能超过4GB,这是因为unzip的缓存位数最大为2的是32次,刚好就是4GB。
当压缩文件超过4GB时,建议使用tar压缩文件再用tar -xvf 数据集.tar 解压;或者安装7zip,使用 7z x 数据集.zip 进行解压。
环境配置
成功上传代码以及数据集之后,在开始模型的训练之前需要配置好代码运行所需要的环境。
在创建服务器实例时,已经预装好了python环境以及Pytorch框架,现在使用环境管理器Conda查看一下现有的环境。
1 | conda env list # 列出所有环境 |

可以看到目前只有base一个环境,而我们正处在base环境下。如果你的命令行左侧没有显示(base)的话,使用 conda activate base 来激活base环境,之后再查看左侧是否出现 (base)。
然后查看当前环境下都装了哪些python包。
1 | pip list # 列出已安装的 Python 包以及它们的版本号 |

除了常用的包外,可以看到base环境中也已经预装好了我们在创建服务器实例时选择预装的Pytorch2.0.0。
然而除了预装的包外,我们在编写代码的过程中引入的许多外部包并不在当前环境内。我们可以选择一个一个定位缺少了哪个包,并使用 pip install 包名 的方式在当前环境中下载这个包,当然还有一种更高效的方式,即通过配置文件快速配置环境。
我们在本地(非服务器端)激活代码可以运行的环境 conda activate base ,通过以下命令生成该环境的配置文件:
1 | pip freeze > ./requirements.txt # 在当前目录下生成 requirements.txt 配置文件 |
该命令会在当前目录下生成base环境的配置文件requirements.txt,其中包含了这个环境下的所有包以及其对应版本信息。将配置文件requirements.txt上传到服务器端,在服务器命令行中切换到配置文件所在的目录,运行以下命令:
1 | pip install -r ./requirements.txt # 根据配置文件配置环境 |
该命令会下载服务器环境中相较于配置文件中缺失的包,当安装完成后服务器端就有了跟本地环境中相同的包。
通过生成环境配置文件的方式,不仅能快速配置环境,在单人应用场景下也可以用来保存实验所处的包环境,有利于他人对实验结果的复现。
pip换源
我们使用的很多包都是第三方的,需要访问国外的资源,国内访问国外资源时速度很慢且可能访问不到,所以需要换源,从国外的资源换为国内的镜像资源从而获取更快的下载速度。
pip换源有以下几种方法:
修改配置文件(长期有效):
配置文件的位置
- Windows:
%APPDATA%\pip\pip.ini - Linux:
~/.pip/pip.conf
- Windows:
在配置文件中添加以下内容
1
2[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple/
使用命令行参数(临时有效):
在
pip命令中使用-i指定源1
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ 包名
修改环境变量(临时有效):
设置环境变量
PIP_INDEX_URL来指定源1
2export PIP_INDEX_URL=https://pypi.tuna.tsinghua.edu.cn/simple/
pip install some-package
国内常用的源包括:
- 阿里云:https://mirrors.aliyun.com/pypi/simple/
- 中国科技大学:https://pypi.mirrors.ustc.edu.cn/simple/
- 豆瓣:http://pypi.douban.com/simple/
- 清华大学:https://pypi.tuna.tsinghua.edu.cn/simple/
环境管理
当多人共用一台服务器时,为了避免不同人共用同一个环境时安装的包彼此冲突、或是配置好的环境被其他人破坏,建议每个人都创建一个虚拟环境,将彼此的环境隔离开。
1 | conda env list # 查看当前所有的环境 |
1 | conda create -n test python=3.8 # 创建一个名为test的虚拟环境,其中python的版本是3.8 |
通过以上代码,我们在conda中新建了一个名为test的虚拟环境,使用 conda env list 查看发现test环境创建成功,使用 conda activate test 将环境从base切换到test。

使用 pip list 查看当前环境下的包,发现base环境下的很多预装包在test环境下都不见了,说明了base和test两个环境之间相互独立。
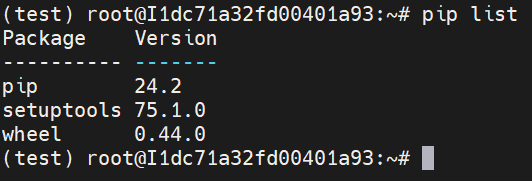
当多人共用一台服务器时就可以通过以上方式将不同人的环境隔离开,从而避免产生冲突。
模型训练
完成代码和数据集的上传以及环境的配置之后,开始模型的训练流程。
假设我们通过 python main.py 运行程序,程序正常启动,并将输出信息打印在终端。然而这种方法的问题是在训练过程中要保持终端始终开启,如果关闭终端那么程序也会中止。
nohup 的作用是让程序在后台运行,并将日志输出到指定的文件中,从而解决以上问题,使程序在终端关闭后仍会在服务器后台继续运行,并将程序运行过程中的输出信息保存在一个指定文件中。
nohup 的语法格式:
1 | nohup 命令 [可选参数] |
示例:
后台运行
1
nohup python main.py &
&表示后台运行该命令- 默认将输出重定向到当前目录下的
nohup.out文件
后台运行并指定输出文件
1
nohup python main.py > log.txt 2>&1 &
> log.txt:将输出重定向到log.txt文件。2>&1:将错误输出重定向到log.txt文件。
假设现在使用 nohup python main.py > log.txt & 运行模型的训练程序

程序后台运行,此时我们ctrl+c退出进行其他操作或者关闭终端都不影响训练的进行。注意10044是程序的进程号PID,如果我们想要中值程序在后台的运行,只需要用 kill指令强行终止该进程。
1 | kill -s 9 10044 # 终止进程,其中 -s 9 指定了传递给进程的信号是9,即强制、尽快终止进程。 |
如果忘记了 nohup 后台运行时的进程号,又想终止程序运行,可以通过以下方式找回PID:
使用
nvidia-smi查看GPU监控
如图为GPU监控信息,可以看到我们的程序目前占用了约4G的显存(共16G),GPU利用率47%。通常最下面的Processes栏位中会显示目前GPU上在运行哪些进程,以及这些进行对应的程序文件,我们可以通过这种方式定位到程序的进程号PID。然而恒源云平台可能限制了权限,导致即使显卡明显被占用但Processes一栏却没有进程信息。
使用
ps -ef | grep python查看带有python关键字的进程
这其实是两条指令
ps -ef和grep python。前者先统计所有进行的信息,
-e参数代表显示所有进程,-f参数代表全格式;后者根据条件过滤进程,输出带有python关键字的进程。
如图,最终我们找到了 python main.py 这条命令对应的10044进程,与前文保持一致,这个进程由7498进程(运行该程序时终端中的python解释器)创建,同时10044进程又开启了10个子进程(与代码中由数据加载器开启的10个进程保持一致)。
通过上述方式找到PID后,通过 kill 命令即可提前终止程序运行。
程序运行过程中会将输出信息重定向到指定文件中,上文中我们通过 nohup python main.py > log.txt & 运行程序,则程序的终端输出都被保存在当前目录下的log.txt文件中,可以通过读取log.txt文件查看输出信息。如果我们想查看模型的实时输出,可以通过以下命令实现:
1 | tail -f log.txt |

tail 命令用于查看文件的末尾内容。它可以显示文件的最后几行内容,默认显示文件的末尾10行。
-n [行数]: 显示文件末尾的指定行数,而非默认的10行。例如,tail -n 20 log.txt将显示文件最后的20行。-f: 持续监测文件是否发生变化,并立即在终端中显示这些新追加的内容。
-f 和 -n 可以一起使用,如 tail -f -n 20 log.txt 用来显示log.txt文件的最后的20行,并持续追踪新增内容。或者单纯的使用 tail -f log.txt 追踪log.txt文件中新增的内容以达到实时输出的效果。




